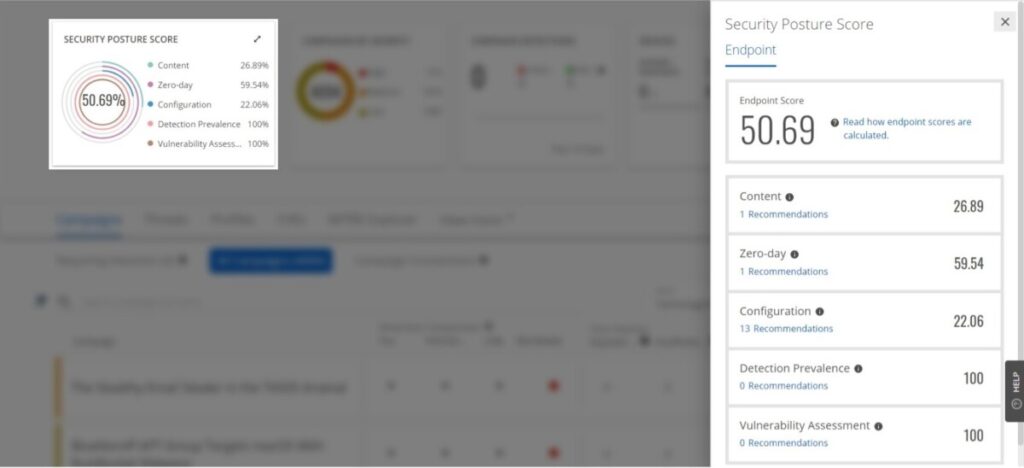
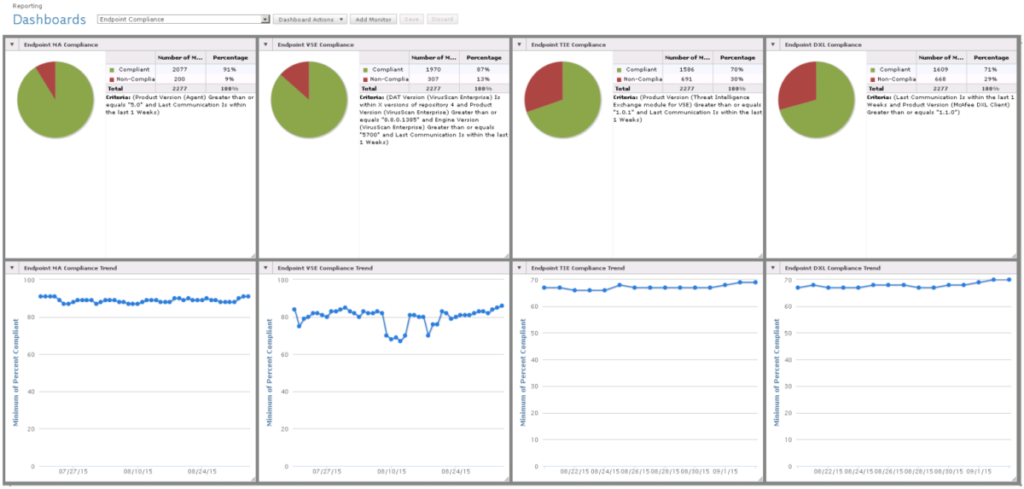
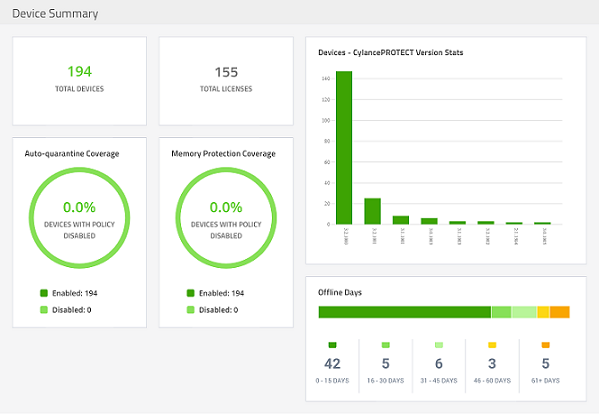
Up until now we have been focused on our own metrics, but what about vendor supplied or created ones? Some tools such as Trellix ePO (shown above) natively provide useful metrics covering the overall security posture, even providing recommendations on how to improve these. In other words, leverage vendor supplied metrics whenever possible.
Since we are dealing with endpoint protection, they will come a time where something suspicious or malicious sis detected. Understanding the detection type e.g. infostealer, ransomware, remote access trojan, and location e.g. laptop, server, department, or business unit provide valuable insights into what is happening in your organization. In fact, let’s take it step further and also correlate threat detections with user and application e.g. browser, MS Office, Windows Explorer.
We once worked with a customer that had a staff member that was trying to download pirated movies. We tracked his behavior starting with his office desktop, then his office laptop, and eventually vis his remote access to the Citrix Presentation Server (aka Remote Desktop Services) farm. Simply accepting the threat detection events without understanding the context and being able to address the issue with the user, would have opened the company up to significant cyber and business risk and liability.
In our previous post about endpoint security, we discussed Operational Compliance, high-level metrics regarding coverage and timely communications. Now we’re going to dive into the technical details of protection. Do note that depending upon the particulars of your endpoint protection, product-specific capabilities and functions will vary.
First let’s consider your tools’ configuration, settings, or tasks – collectively we’ll just call policies. Ideally your management console can indicate that their policies are up to date and even a policy version. If your console does not have this ability, hopefully the local app’s console can indicate this. Without some method to confirm that your apps are doing what they are being told, you have nothing more than assumption of what is in place.
% of endpoints with up to date policies*
* Overall health is important but able to drill down into the details of any out of compliance systems so that they can be remediated.
If your chosen tool uses content updates e.g. signatures, .DAT files, engines, you will want to ensure that your endpoints are kept up to date. With most vendors releasing content on a daily basis, a good rule of thumb is ensuring that your systems are never more than four versions out of date. This threshold allows for reporting delays i.e. if a system is out of the office but online and also if systems are offline. For scanning engines or other content which are not updated as frequently, sticking with no less than a one version difference is good.
% of endpoints with content within n-4 versions
% of endpoints with engines within n-1 versions
These three aforementioned metrics are good, point-in-time snapshots. To really understand your environment, we recommend tracking these over time i.e. collect trends. Ideally your management consoles can be customized to display all of these in one screen, providing you with an at-a-glance view of the health of your organization.
30-day/90-day Trend% of endpoints with up to date policies
30-day/90-day Trend% of endpoints with content within n-4 versions
30-day/90-day Trend% of endpoints with engines within n-1 versions
Tracking trends is an effective way to spot operational anomalies in your environment and remediate them before they become institutional issues. For example, we worked with an organization that outsourced their Internet firewall management. When the supplier “cleaned up” some rules, they inadvertently disconnected their endpoints from the local management console, which also prevented propagation of the policies. Had the endpoint security team not been tracking these metrics, they would have only known about the changes upon encountering an operational issue, or worse a cyber incident.
Let’s now tackle another pillar of cybersecurity, endpoint security.
We’ll leave the debate of antivirus (AV), antimalware (AM), endpoint protection (EP), next gen antivirus (NGAV), or next gen endpoint protection (NGEP), or another day when we can play acronym bingo. We’re going to lump all of these apps that serve, through signatures, behavioral rules, machine learning (ML), or even artificial intelligence (AI), to protection endpoints from malicious apps and activity into one basket.
Regardless of your organization’s size, the first order of business is what I like to call Operational Compliance. Basically we are ensuring that all of your endpoints are protected by the correct apps, and reporting to central management in a timely manner.
In terms of coverage, you should strive for nothing less than 100% coverage, 95% or higher is a good pass in my books. Of course 95% of coverage in a 100-device organization can be easily remediated, but in a 1,000 device organization, 50 non-compliant systems starts to be more daunting to handle. As the saying goes, your mileage may vary – all depending upon your organizations risk appetite.
We’ve already established that knowing the number of assets in your organization is key, We’re just building on the principle. That said, there are times where a system may need your AV/EP temporarily removed or disabled for troubleshooting purposes. Application vendors do tend to blame security for most issues don’t they? So we should allow for those exceptions. Exceptions, though, should not linger and become the norm.
% Endpoint Coverage (deployed / (total systems – exceptions))
# of Exceptions or better yet # of Exceptions older than two weeks
Now let’s consider the versions. Just like any application, your AV/EP will require periodic updating, patching, or upgrading. And just like any other application, you should be running recent (the latest n, or n-1) versions excluding any compatibility issues. A pie cart is a good way to visually and quickly understand the state of your environment. If your AV/EP tools utilise several modules, you’ll need to duplicate these efforts for each of these, as well if your systems require a separate management agent. For larger organizations, segmenting this data by business unit or asset type can be helpful in order to direct resources to investigation.
# Deployed versions of AV/EP
# Deployed version of AV/EP by business unit or asset type (servers, workstations, laptops)
Last is where the proverbial rubber meets the road. It does us no good to deploy software if we can’t ensure that it is operating normally, have the latest policies and settings, or have reported back to the management console. Generally speaking I like to ensure that all endpoints have checked in at least once a week. Exceptions such as being out of the office can be easily managed simply by bringing these systems online. You would anyways be doing this as part of your patch management process right?
% of assets with successful communication within n-days
Your AV/EP architecture and management console will largely dictate how easy all of this information is gathered or reported. While automatic/scheduled export/delivery is ideal, at the very least be able to easily extract the information if manual efforts are required. As the expression goes, your mileage may vary.
Let’s bring this topic home and cover what we want to do about them, because we are going to do something right? We patch, remediate, and mitigate in order to reduce the exploitability of the asset in question.
Ideally your business and or asset owner should be indicating how long they are willing tolerate being exposed. Turning cybersecurity into a business decision is a bigger discussion for another day so let’s seed this discussion with a 30-day window. Why 30-days? Simply because we are all very used the cadence of Patch Tuesday – Microsoft, Adobe, Oracle and few others’ regularly scheduled release of updates. If we can patch our systems within 30-days, we don’t have to deal with complications of overlapping updates. Don’t forget that there are many vendors that may have their own update cadence and that many vendors may release out-of-band updates to address more critical issues.
The typical small to mid-sized enterprise (SME) that operates 9×5 should be able to adhere to the 30-day target. For all others, you may have to have different targets depending up the type of asset. For example, you may choose to allow non-critical assets to be patched within 45-days. See previous posts regarding asset categories.
Yes, that is a strong password, but the sticky note needs to be hidden under the computer!
In our previous post, we determined that we need to organize our assets based upon their context. With that in mind, let’s consider what vulnerabilities matter to us.
The oblivious place to start is the Common Vulnerability Scoring System (CVSS). Taking into account factors such as attack vector, complexity, privileges and user interaction, CVSS provides standardized way to assess the severity of security weaknesses. Sounds great right? Before you answer, consider the real-world context. Does a Critical vulnerability on a trivial asset, let’s say an intern’s laptop, matter as much as a Medium vulnerability on your mission-critical communications server? Ceteris paribus, eventually yes that laptop is concerning, but probably not in the immediate future.
Obsolete, end-of-life, of end-of-support, software is its own class of vulnerabilities. In most cases, the vendors no longer offer support or updates for these, so your only recourse is to upgrade, seek an alterative, or uninstall.
Another significant class of vulnerabilities are those that are known to be exploited. These are worth tracking anywhere in your organization. The U.S. Cybersecurity Infrastructure Security Agency (CISA) is one of several organizations that maintains a list of Known Exploited Vulnerabilities (KEV).
The last class of vulnerabilities to consider at this time are those with no remediation. Note that I did not specify patch. Remember that some vulnerabilities are simply misconfigurations such as a default password left in operation. The lack of remedy could simply be because a fix has not yet been developed. Or worse, a remediation might be incompatible with the system or might create other problems such as creating performance issues. In either case we’re dealing with vulnerabilities with no solution in sight.
In summary, so far we’re working with:
Severity
End-of-life/end-of-support software
Known exploited
Vulnerabilities with no remediation or mitigation
Let’s now include some context and we have the following to get started:
Known Exploited Vulnerabilities for any asset or group
High-severity for Critical systems
Rated vulnerabilities for all non-Critical systems
Any severity above Informational (rated) for Internet-facing systems
End-of-life/end-of-support softwareby business unit
Next week, we bring this topic home when we also consider remediation/mitigation efforts.
There are two critical vulnerabilities in the image, can you spot them?
Stated simply, vulnerabilities are weaknesses that attackers can exploit to gain unauthorized access or cause harm. Mitigating a vulnerability usually entails patching, updating, reconfiguring, or applying a compensating control. Sometimes though mitigation may not be possible due to a lack of a patch or because the patch might be incompatible with other parts of the system.
But before we can discuss measuring vulnerabilities, we need to really understand where we are measuring them. Is uniformly measuring all assets (devices, systems, operating systems, applications, etc) appropriate? If our organization only consisted of five laptops, all running the same software for users to perform the same work, maybe. But for any reasonably sized organization, a server has greater business value than a single user’s desktop. The CEO’s laptop is going to have greater business value (operationally) than a receptionist’s desktop. And for a final example, a public-facing system will be of greater value than a test system. In other words we must establish levels of criticality or importance to business functions.
Here are some examples of asset categories that will help to define our vulnerability metrics, keeping in mind that an asset might belong to several categories simultaneously.
Critical vs non-critical
Tier 1 (production) vs Tier-2 (supporting) vs Tier-3 (test/development)
Internet-facing
Contains sensitive data e.g. customer or financial
VIP users : CEO, CFO, HR managers i.e. high value targets
Business unit
Thinking ahead, once you apply your policies and processes to the asset groups, your work is simplified to managing these groups as assets or commissioned or decommissioned.
In reference to this post’s image, the first vulnerability should be obvious, the zip tie. The second is the Master lock. While wildly popular and mainstream, they are some of the easiest to defeat.
Administrative or privileged accounts are the holy grail for threat actors because they are the proverbial and literal keys to the kingdom.
Since Windows Active Directory is the most popular network operating system, we’ll focus our efforts on domain environments.
For IT administrators of a certain age, there are certain hard-to-break habits that persist. These include granting end users local administrator rights, making certain users e.g. managers Domain Admins, and the most egregious in my opinion, making their own user accounts a Domain Admins.
This can be quite an expansive topic so we’re going to focus on certain fundamentals to get the proverbial party started:
Set aside the default Domain Administrator account with a strong password kept under lock and key
Minimize privileged account sprawl
Enforce separate user and admin accounts for IT staff
Require multifactor authentication (MFA) for all privileged accounts
Monitor for and alert on undesirable privileged account activity
Monitor for and alert on privileged user group changes
Minimize the following key metrics for best results:
# of accounts with administrative permissions
# of privileged accounts without MFA enabled
# of privileged accounts with passwords older than 1-year(your mileage may vary)
# of inactive privileged accounts i.e. with no logon in last 30-days
Frequency that the default Administrator account has been used
Frequencythat privileged user groups have been changed
Frequency of privileged account failed logins, lockouts, unlocks, and password resets
We could go on and on with regards to auditing. Seriously we could go on and on, and will do so at a later time. For now, this should get you started on the straight and narrow.
Now that we can measure what’s connected to our organization, let’s see what’s running (installed). As with the previous posts, we’re going to initially focus on our local systems.
Consider what is running in your environment. The obvious things are productivity applications such as MS Office, collaboration software, and web browsers. Speaking of web browsers, what about plug-ins and extensions? Also consider any hardware enabling drivers, their supporting apps, and of course all of your security software. You’re probably thinking that this list is getting big.
But wait, there’s more! The two most important bits of software have yet to be mentioned: the computers’ operating systems (OS) and firmware (BIOS). The OS probably just slipped your mind but you probably didn’t consider the BIOS. Without a working BIOS, your computer is just a mess of metal and electronic circuits. It is the firmware which turns that pile of stuff into a computer, and enables the OS to load and run. And yes, you really need to manage the firmware along with everything else. Don’t worry though, there is an app for that!
Let’s recap the various bits of software that we should be measuring:
BIOS/firmware
Operating Systems
Drivers and hardware enablers
Applications
Application add-ons e.g. Browser Helper Objects
The more versions and variations of these, the greater the risk from misconfigurations, vulnerabilities and exploitation, and the greater the effort and time required to manage. Therefore we want to have a few of these as possible in order for the business to function i.e. establish a common operating environment (COE).
A common operating environment’s benefits include but are not limited to:
Increased efficiency and productivity
Reduced costs
Improved collaboration and communication
Enhanced security and compliance
In terms of metrics, here are some to get you started. For simplicity with this list, we’ll refer to all items in the previous list as apps. Minimize these for best results and there are bonus points for having these broken down by business unit.
# of different app versions
# of end-of-life/end-of-support apps
# of unauthorized / non-COE apps
# of authorized / COE apps not used in the last n-months
In this final installment of Enterprise Asset Management metrics, we’re going to connect these with the business, specifically in terms that the business understands.
Let’s recap what we’re working with:
% of active vs inactive systems
% of managed vs unmanaged systems
% of known vs rogue devices
Ultimately, we’re deal with a matter of management or control. If we can manage it, we can manage the risk. These metrics all serve the underlying purpose of maximizing management and minimizing risk,
The traditional and dare I say legacy approach to procurement is to say something like “We need $1M for a network access control system that also means we’re going to have to replace all of our network equipment for compatibility” and then you launch into the vendor presentation. The typical executive’s eyes are going to go vacant quite quickly!
Instead try something like this: “How much exposure are you, the business, willing to tolerate from unauthorized devices operating on the network?” Their answer may be a resounding none, until they hear that there is a $1M price tag for a completely automated system. They’ll likely ask for an alternative proposal. So then you can offer five-day tolerance for $250K. Now there is a clear business decision which can be made.
Assuming they choose the second option, you have a working budget without even needing to explain the tool being used. You might choose to invest in a new asset/patch management tool, a vulnerability management service, and even some training for your staff. What started out as an ask to fix one issue, became a win across multiple areas!
In our next post, we’re going to discuss Software Asset Management.
Now that we have practical set of metrics, how to we obtain them?
% of active vs inactive systems
% of managed vs unmanaged systems
% of known vs rogue devices
For an SMB/SME, there are a few options which, when combined, will provide you with a highly accurate snapshot of your organization.
Starting with user systems, the following tools have valuable data, to be combined to form your basic asset register.
Active Directory – Everything about domain-joined systems is found somewhere in here.
Asset/Application Management – Ideally you need a tool that synchronizes automatically with Active Directory both adding new domain-joined systems to management as well as removing recently removed domain-joined systems from management.
AuditingLog Management – A good tool can identify active vs inactive systems, by collecting network-wide data and by taking cues from Active Directory.
Endpoint Security – You wouldn’t dream of running a system without some sort of managed endpoint security would you? So you should have very high coverage here. Extra points if you automatically synchronize with Active Directory.
Network Management – A unified network system i.e. a single pane of glass for all switches, firewalls, and wireless is ideal and would allow you to passively monitor everything.
Vulnerability Management – Scanner(s) are a great way to actively discover what is on your network and explicitly beyond what is expected to be found.
Now let’s consider unmanaged systems. Since we have already established that unmanaged systems aren’t in Active Directory, you’re going to need to leverage your non-AD capabilities such as Network and Vulnerability Management. These two also help with known vs rogue devices. You have probably noted a trend.
For best results:
Use a combination of active (AD-aware, network scanner) and passive (network management) tools. Leveraging multiple sources for your asset information reduces the risk of a single tool providing inaccurate or incomplete information.
The appropriate choice of tools provides value beyond their immediate purpose. For example your asset management tool might provide information about network assets and your network management tool might provide information about your systems.
In Part 3, the rubber meets the road where we fully connect the technology dots to the business.